機械学習とは何か
新規作成:2016年10月16日
最終更新:2016年11月03日
機械学習とは、次にどのようなデータが来るのかを、決まった手順を踏んで予測する技術、あるいは手法のことです。
機械学習の良いところは、予測のための「手順」を、過去のデータからほとんど自動で見つけられることです。
この記事では、機械学習とは何か、その基礎と考え方について説明します。
目次
- 機械学習とは何か
- 機械学習と汎化誤差
- バイアス・バリアンス・ノイズ
- 機械学習を勉強してから使ってみるまでの流れ
スポンサードリンク
1.機械学習とは何か
機械学習とは、次にどのようなデータが来るのかを、決まった手順を踏んで予測する技術、あるいは手法のことです。
機械学習の良いところは、予測のための「手順」を、過去のデータからほとんど自動で見つけられることです。
機械学習の目的は「まだ手に入れていないデータを予測すること」です。
機械学習は、プロセスがどうであれ、「とにかく予測が当たればよい」ということを目的としています。
予測を当てるために、過去のデータを使います。
例えば「気温が高くなるとビールが多く売れる」というデータが過去にあれば、「明日気温が高ければ、ビールは多く売れるだろう」と予測します。
このとき重要なことは「気温が高ければ、売り上げが増える」と人間が指定するわけではないことです。
過去のデータをみて、文字通り「機械」が勝手に「学習」します。だから機械学習と呼ばれます。
「気温が高くなるとビールが多く売れる」といった関係性を「パターン」とも呼びます。
機械学習は、データからパターンを自動で見つけ出し、見つかったパターンを使って予測を出します。
2.機械学習と汎化誤差
汎化誤差とは「まだ手に入れていないデータを予測した時の誤差」のことです。
機械学習の目的は「まだ手に入れていないデータを予測すること」でした。
その目的をどれだけ達成できているのかを評価するために、汎化誤差が使われます。
機械学習の目的は、言い換えると「汎化誤差の小さな予測を出すこと」と言い換えることができるわけです。
なお、汎化誤差が小さいことを、「汎化能力が高い」とも言います。
機械学習は、学習させておしまいではありません。
データからパターンを学習させて、予測を出し、そして汎化誤差が小さくなるように調整します。ここまでやらなければ「予測は出すには出したんだけれども、まったく当たらない」ということにもなりかねません。
予測を出すことと、予測を評価することは、常にセットで考えなければならないことに注意してください。
3.バイアス・バリアンス・ノイズ
汎化誤差は、バイアス、バリアンス、そしてノイズの3要素に分けることができます。
機械学習の目的である「汎化誤差の小さな予測を出すこと」を達成するためには、汎化誤差についての理解が不可欠です。
順に説明します。
バイアス
バイアスは、予測モデルが単純すぎることが原因で発生します。
下の図は、縦軸に去年のビールの売り上げを、横軸に月を指定した架空のデータです。各調査日の売り上げを黒丸(●)で示しています。
去年の売り上げデータを使って、今年のビールの売り上げを予測してみました。予測値を赤い線であらわしています。
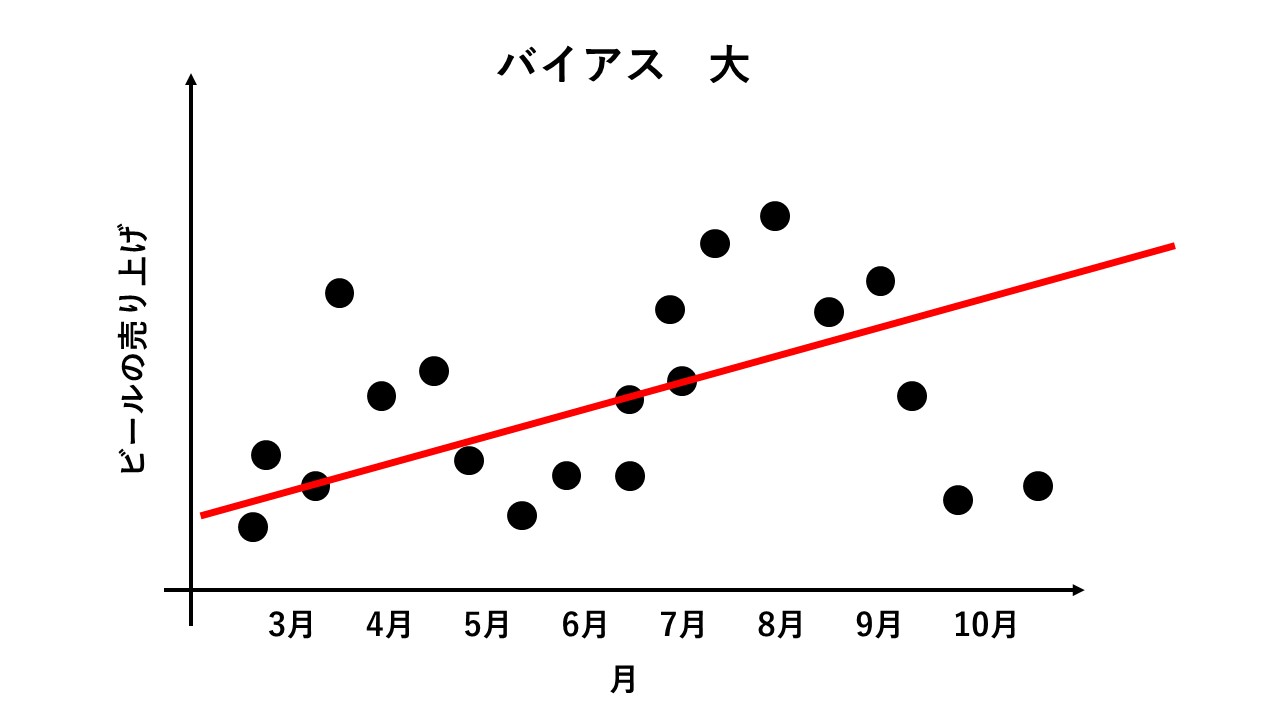
予測値は、右肩上がりの直線となっていますが、実際のデータは、4月や8月にピークが見られます。お花見シーズンや、暑くなった季節にビールが良く売れるという関係を見逃してしまっています。
これが、バイアスが大きな、ダメな予測です。バイアスが大きければ、精度の高い予測を出すことはできません。
バリアンス
バリアンスは逆に、予測モデルが複雑すぎることが原因で発生します。

例えば、去年の4月2日に大規模な飲み会が発生したとします。そのため、ビールの売り上げも増えました。
しかし、今年も4月2日に飲み会が発生するという保証はありません。それなのに、4月頭にすごくビールが良く売れるという予測を出すことは不適切だと考えられます。
バリアンスは、「データが変わることによって発生する誤差」とみなせます。
去年のデータを鵜吞みにして、すごく複雑な予測を出してしまうと失敗してしまうということです。
過去のデータを重視しすぎてしまう失敗のことを「過学習」とも呼びます。
過学習が起こると、過去のデータへの当てはまりはとてもよくなりますが、まだ手に入れていないデータ、あるいは未来のデータへの予測精度は落ちてしまいます。すなわち、汎化誤差が大きくなってしまいます。
ノイズ
ノイズは、どうやっても減らすことができない誤差のことです。
これが残ることは仕方ありません。
バイアスとバリアンスのトレードオフ
単純すぎる予測だと、バイアスが増え、複雑すぎる予測だと、バリアンスが増えてしまいます。
両者には、片方をよくするともう片方が悪くなるというトレードオフの関係があります。ここを抑えたうえで、下の図のような、「単純すぎず、複雑すぎない予測」を出す必要があるのです。
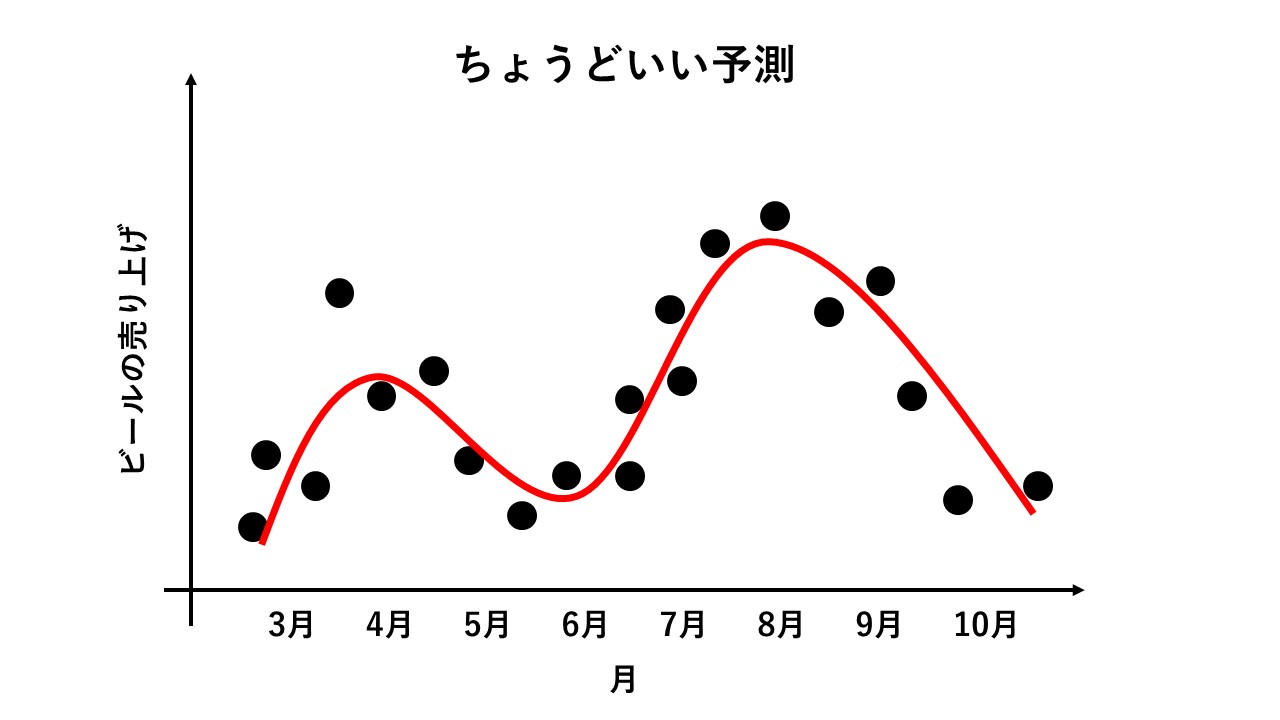
機械学習法の多くは、この問題をクリアするために、様々な工夫をしています。
新しい機械学習の手法を学ばれるときは
- バイアスの減らし方(複雑なデータへの当てはまりを向上させる方法)
- バリアンスの減らし方(過去のデータへの当てはまりを過剰に良くしないための方法)
の2つを抑えておくとよろしいかと思います。
4.機械学習を勉強してから使ってみるまでの流れ
機械学習の勉強の流れをざっとまとめてみます。
簡単にまとめると以下の通りです。
- 機械学習の全体像を知る
- 個々の手法を知る
- 予測の評価手法を知る
- 機械学習を自分の課題に使ってみる
機械学習の全体像を知る
機械学習といっても、様々な手法があります。
「気温が高くなるとビールが多く売れる」というパターンを表すだけでも、たくさんのやり方があるんですね。
そして、各々のやり方には、あまり関連性がないこともあります。
機械学習の参考書を読むと、個別の手法の列挙となっている本も珍しくありません。
「まだ手に入れていないデータを予測する」という目的を持ち、予測のための「手順」を過去のデータから自動で計算ができるというのであれば、それは機械学習と呼ばれます。そのため、一見するとバラバラにも見える、たくさんの手法を学ぶ必要があります。
すべての手法を網羅する必要はないでしょう。
ただ、よく使われる、言い換えると「比較的簡単に計算できて、予測精度が高い」手法は、使えるようになっておくほうが良いです。
そのような手法としては、例えば以下の手法が挙げられます。
- 一般化線形モデル
(重回帰分析・ロジスティック回帰が含まれます) - 一般化加法モデル
- k最近傍法
- ニューラルネットワーク
- サポートベクトルマシン
- 樹木モデル
- ランダムフォレスト
どれも比較的古くからある手法で、Rを使えば簡単に計算ができます。
古いといっても、まだまだ現役。予測精度も高い、大変優秀な手法です。
上記の手法を使ったという論文も、どんどん世に出ています。
そのうえで、ちょっと新しい手法にも手を伸ばしてみるのが良いと思います。
- 勾配ブースティング
- 深層学習
まずは、機械学習の目的が予測であることと、機械学習にはたくさんの手法があるということを理解してください。
個々の手法の勉強の進め方
個々の手法を学ぶにあたっても、いくつかの階層があると思います。
- 考え方を学ぶ
- 推定方法を学ぶ
- 実装方法(プログラムの書き方)を学ぶ
- 応用してみる
個人的には、「個々の手法のおおざっぱな考え方」と「モデルの推定の理論」は分けて勉強するほうが良いのではないかと思います。
例えば、線形回帰の場合、「散布図に線を引っ張る」という考え方と「最小二乗法」というパラメタ推定の方法は別に学ぶのが自然です。
また、R言語などを使って実装する場合は、モデルの推定方法についてそこまで深い知識は求められません(ある程度は知っていたほうがエラーに対応しやすいです)。
そのため、このサイトでは「考え方」と「実装方法(主にR言語)」について解説をしていく予定です。
ただし、推定方法については勉強しなくてもいいというわけではありません。あくまでも、当サイトで説明される量がちょっと少ないよという話だとご理解ください。
参考文献
|
はじめてのパターン認識 名前の通り、初めて学ぶ人にとってちょうど良い入門書です。 機械学習とパターン認識の概要と、k最近傍法やニューラルネットワーク、サポートベクトルマシンにランダムフォレストといった各種法の概要など、幅広く載っています。 まずはこの本から機械学習を学ばれるという方は多いかと思います。 |
 |
|
データサイエンティスト養成読本 機械学習入門編 雑誌のような体裁の本です。機械学習の理論について細かく載っているわけではありませんが、大枠をつかむ入門資料として、良い本なのではないかと思います。 |
 |
スポンサードリンク
