Pythonで学ぶあたらしい統計学の教科書 [第2版]:サポートページ
『Pythonで学ぶあたらしい統計学の教科書 [第2版]』のサポートページです。
ありがたいことに、『Pythonで学ぶあたらしい統計学の教科書』の初版は、中国や韓国など海外も含めて、多くの方にお読みいただきました。心よりお礼申し上げます。
しかし初版は出版から年月が経ってしまい、Pythonコードをそのまま実行しにくいことがしばしばありました。
コードの刷新だけでなく、初学者が独学しやすくなるよう、記述統計や、推測統計編におけるシミュレーションなどを大幅に増やし、150ページほど追記した第2版を出版することになりました。
この記事では、書籍の特徴などの紹介をしています。
本書で使用したサンプルデータと実装コードは、すべてGitHubから参照できます。
【2022年6月22日追記】
ファイルのダウンロード方法がわからない方はここを見てください
【追記ここまで】
数理的な面については『統計学 計算ノート』で補足的に説明をしています。
計算ノートでは、単回帰分析における推定量の性質などを、式変形をほとんど省略せずに解説しています。
|
Pythonで学ぶあたらしい統計学の教科書 [第2版]
|
 |
目次
1.基本情報
出版社 : 翔泳社
著者 : 馬場真哉(このサイト、Logics of Blueの管理人です)
タイトル : Pythonで学ぶあたらしい統計学の教科書 [第2版]
発売日 : 2022年6月08日ごろ(一部店舗では先行発売などがあります)
簡易目次 :
第1部 統計学をはじめよう
第2部 PythonとJupyter Notebookの基本
第3部 記述統計
第4部 確率と確率分布の基本
第5部 統計的推定
第6部 統計的仮説検定
第7部 統計モデルの基本
第8部 正規線形モデル
第9部 一般化線形モデル
第10部 統計学と機械学習
本体価格は3300円です(消費税10%で、税込み3630円となります)。
2.書籍の特徴
テーマ
書籍のテーマは、初版から変わっていません。1つ1つの内容は、できる限りブラッシュアップしました。
「確率変数や確率分布という用語がなぜデータ分析に必要となるのか」といった基礎の基礎から、区間推定や統計的仮説検定、そして統計モデルや機械学習とのつながりまで、少しずつステップアップしていくような構成になっています。
大きな特徴は、区間推定や仮説検定で終わるのではなく、統計モデリングまでが対象であることです。
回帰分析や分散分析だけでなく、ロジスティック回帰分析やポアソン回帰分析など一般化線形モデルも解説しています。
扱うテーマが多岐にわたるため、書籍の書き方を工夫しました。
まずは、「日本語・数式・Pythonコードで3回同じことを説明する」というやり方です。個別のテーマに関する理解度を高めるために導入しました。前段についての最低限の理解をした後で次に移る構成になっています。
テーマ同士の関連を理解していただくために、節を細かく分割し、「用語」「実装」というヘッダーを節のタイトルに付けました。自分が今、何を学んでいるのかを整理しながら読み進めていただくためです。
例えば「用語」の節で分散の意味と数式による定義を解説し、次の「実装」の節でPythonで実装する方法を解説する、という流れです。
自然な流れで勉強できますし、目次を見ただけで書籍の流れがつかめるという意味で便利だと思います。
実務面に配慮して、パッケージは有名なものだけを使いました。仮説検定はscipyを多用し、統計モデル(正規線形モデル・一般化線形モデル)ではstatsmodelsを中心に使いました。両者ともに、短いコードで効率的に実装できます。細かいことを書くと、statsmodelsによるモデリングの際はstatsmodels.formula.apiを中心に使い、例えば『sales ~ temperature』のように『応答変数 ~ 説明変数』のformula形式で実装する方式を採用しました。これはR言語でも採用されているもので、直観的にモデルの構造を指定することができます。第2版ではformula構文について若干の解説を追記しました。
グラフはほぼすべてseabornの使用を前提としているので、単にmatplotlibを使うよりも美麗なグラフが描けます。グラフのコードにもこだわりました。整然データというデータ形式を重視したため、短いコードで美しいグラフが描けます。整然データについては本文中で説明があります。
初版との違い
第2版では記述統計についての記載も増やしました。例えば平均値「だけ」を見るようなデータ分析がもたらす問題、平均値「だけ」を見る分析からの脱却方法としての度数分布の利用、といったデータを扱う上でとても大切な技術や考え方を、ページ数を割いて解説しました。層別分析のような実用的に大切な技術も、章を分けてしっかり解説しています。
Pythonを使って、手を動かしてデータを分析してみたいという方に、さらにマッチする内容を目指しました。
独学がしやすくなるよう、初歩の初歩から順を追って解説するように、初版から構成を見直しました。
Pythonの初歩→記述統計→確率論の初歩→推定→検定→統計モデル(一般化線形モデル)→機械学習、と順を追って解説しています。
対象読者
統計学を勉強してみたいという初学者の方が本書の対象読者です。
手を動かしながら統計学を学びたいという方は、本書が特にマッチすると思います。初版と比べて独学しやすい構成にしたので、読み進めやすくなったと思います。
また、統計学を勉強したことはあるが、推測統計の理論に納得がしにくいという方も、本書の対象読者です。
本書ではシミュレーションを多用しました。様々な確率分布や単純ランダムサンプリングなどを、1つ1つシミュレーションして確かめていき、推測統計の理解を深めることができます。
書籍の構成
詳細な内容を紹介します。
第1部:統計学をはじめよう
第1部では統計学を学ぶモチベーションを与えるために、統計学の基本的な考え方と、統計学を学ぶご利益を解説します。平均値だけを見るような単純な分析方法が持つ問題点などを理解してください。
第2部:PythonとJupyter Notebookの基本
第2部ではプログラミング言語であるPythonを導入します。
第1章ではインストールの方法を解説します。
第2章ではPythonプログラミングをするための便利なツールであるJupyter Notebookの使い方を解説します。
第3章では四則演算から繰り返し構文まで、Pythonの基本文法を解説します。
第4章ではデータ分析をするための便利な機能を利用するために、numpyとpandasと呼ばれるライブラリの使い方を解説します。
第3部:記述統計
第3部ではデータの集計をする技術である記述統計を解説します。
第1章ではデータにまつわる用語を紹介します。
第2章ではΣ記号などの数式の読み方をやさしく解説します。
第3章では度数分布とヒストグラムを解説します。
第4章では1変量データを集計する技術を解説します。平均や分散などさまざまな統計量を導入し、1つ1つPythonで計算する方法を解説します。
第5章では多変量データを対象にして、データ同士の関連性を探る方法を解説します。
第6章では魚種別や性別あるいは地域別といったグループ別に分析を行う方法を解説します。実務的にも役に立つ技術です。
第7章ではデータの可視化の方法を解説します。matplotlibとseabornというライブラリを使い、美麗なグラフを簡単に描く方法を解説します。
第4部:確率と確率分布の基本
第4部では推測統計への序章として、確率と確率分布の初歩を解説します。
第1章では集合の基本的な用語から始めて、確率論の初歩を解説します。
第2章では確率分布を導入し、その基本的な扱いを解説します。
第3章では代表的な離散型の確率分布として二項分布を解説します。
第4章では代表的な連続型の確率分布として正規分布を解説します。
第3章と第4章では、シミュレーションを使って、なるべく直観的に確率分布を理解できるように配慮しました。
第5部:統計的推定
第5部では統計的推定の問題を扱います。
第1章では標本という手持ちのデータから母集団という全体について議論するための基本的な方針を解説します。
第2章ではPythonを使って、母集団からのサンプリングを行うシミュレーションを実施します。
第3章では母集団の平均値、すなわち母平均の推定問題を扱います。推定に関する基本的な用語の解説と、シミュレーションを併用した推定の考え方についての解説を行います。
第4章では第3章とほぼ同じ流れで、母集団の分散、すなわち母分散の推定問題を扱います。
第5章では母集団分布に正規分布を仮定したうえで、標本から計算された統計量が従う標本分布を導入します。複数の確率分布が新たに登場しますが、すべてシミュレーションを使ってなるべく直観的に導入します。
第6章では標本分布を利用して区間推定という問題に取り組みます。
第6部:統計的仮説検定
第6部ではデータに基づいて判断を下すための手法である統計的仮説検定を扱います。
第1章では母平均に関する1標本のt検定と呼ばれる手法を通して、統計的仮説検定の基本的な考え方を解説します。
第2章では平均値の差の検定を解説します。
第3章では分割表の検定を解説します。
第4章では統計的仮説検定の結果を解釈するときの注意点などを解説します。
第7部:統計モデルの基本
第7部では統計モデルを導入し、基本事項とモデルを構築する手続きを解説します。
第1章では統計モデルに関する用語を導入し、統計モデルを学ぶご利益を紹介します。
第2章では線形モデルと呼ばれるモデルを対象にして、モデルを構築する手続きの概要を解説します。
第3章ではさまざまなモデルの名称を紹介します。
第4章ではモデルのパラメータを推定するための方法論として、最尤法と呼ばれる方法を解説します。
第5章でもモデルのパラメータの推定を扱いますが、こちらでは最小二乗法と呼ばれる方法を解説します。そして最尤法と最小二乗法の関わりを解説します。
第6章ではモデルの評価の方法と、モデルに用いる変数を選択する方法を解説します。
第8部:正規線形モデル
第8部では正規線形モデルと呼ばれるモデルの解説を通して、回帰分析や分散分析について解説します。
第1章では単回帰分析と呼ばれる分析手法を導入します。
第2章では残差診断を通して分析結果を評価する方法について解説します。
第3章では分散分析と呼ばれる検定手法について解説します。回帰分析と分散分析のかかわりについても解説します。
第4章では複数の変数を扱うモデルを解説します。複数の変数がある場合に単純な比較を行うのが好ましくない理由と分析の方法を改善する方法を解説します。単純な分散分析を使う際の注意点なども紹介します。
第9部:一般化線形モデル
第9部では正規分布以外の確率分布をモデル化する方法として、一般化線形モデルを解説します。
第1章では一般化線形モデルの導入的解説をします。
第2章では「ある/ない」といった二値のデータを分析するための手法であるロジスティック回帰分析を解説します。
第3章では一般化線形モデルの残差について解説します。
第4章では「0個、1個、2個、……」といった離散型の数値を分析するための手法であるポアソン回帰モデルを解説します。
第10部:統計学と機械学習
第10部では機械学習の導入的解説をします。
第1章では機械学習に関わる用語を導入します。
第2章では正則化と呼ばれる技法と、この技法を使って回帰分析を拡張したRidge回帰とLasso回帰を導入します。
第3章ではRidge回帰とLasso回帰をPythonで実行する方法を解説します。
第4章ではニューラルネットワークの導入的解説をします。そのうえで一般化線形モデルとニューラルネットワークの関係を解説します。
本書に載っていないこと
本書では数理統計学の教科書のような厳密な証明などは大きく省略しています。
また、深層学習などやや高度な機械学習の技術についても載っていません。
3.本書のサポート情報
本書で使用したサンプルデータと実装コードは、すべてGitHubから参照できます。
【2022年6月22日追記】
ファイルをダウンロードする場合は、下記画像を参考にして、まずは緑色の「Code▼」をクリックして、その次に「Download ZIP」をクリックしてください。
登録などは一切不要で、ファイルをダウンロードできます。ZIPファイルとしてダウンロードされます。ダウンロードしたファイルを右クリックして「すべて展開」してご利用ください。
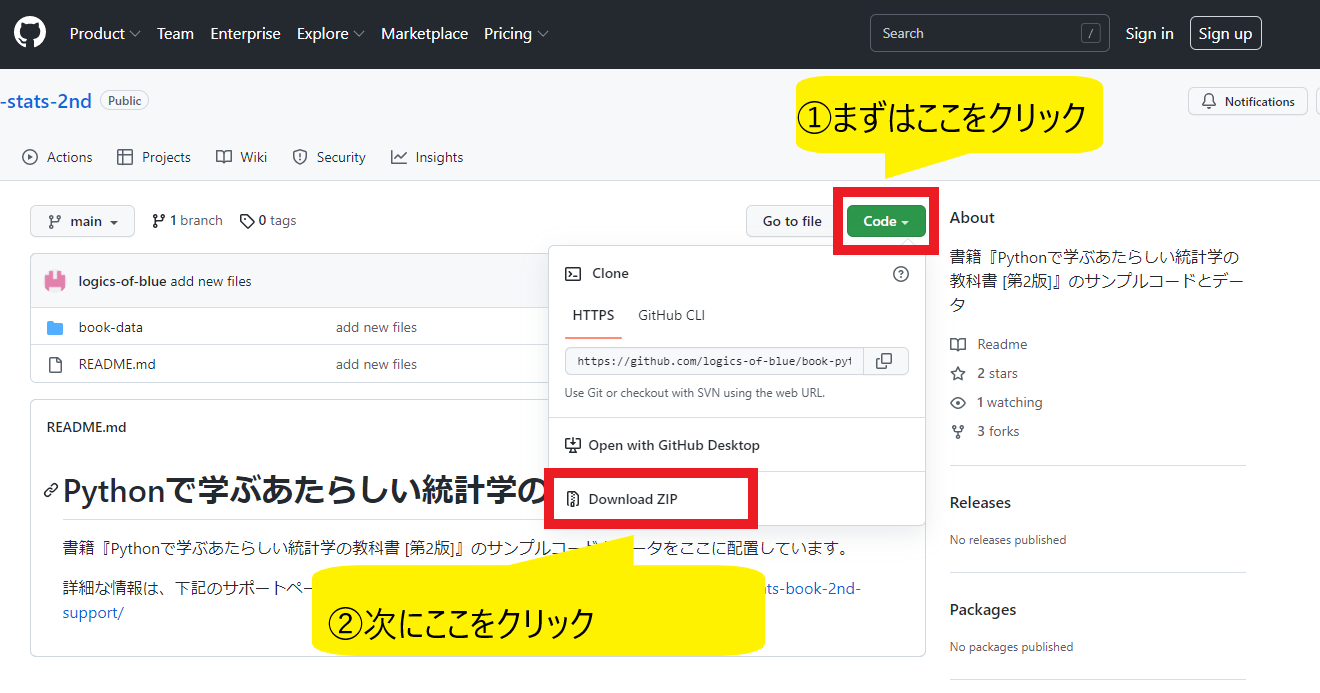
【追記ここまで】
更新履歴
2022年05月25日:新規作成
2022年06月11日:『統計学 計算ノート』のリンクを追加
2022年06月22日:ファイルのダウンロード方法の補足を追記

Git Hubからのcsvデータの取込方法は結構癖があるので、手順を補足いただいた方が初心者には親切かと思います。(結構、ここでトラップにはまっているので)
大塚様
コメントありがとうございます。
管理人の馬場です。
おっしゃる通りですね。
ファイルのダウンロードの方法を追記しました。
建設的なコメント、ありがとうございます。
初歩的な質問で申し訳ないのですが、ZipCodeをダウンロードした際、各csvファイルの名称が文字化けしてしまいます。
この文字化けの対策はございますでしょうか。
返信が遅れて失礼しました。
拙著のサンプルデータはほとんどが半角英数字のみですので文字化けしにくいかと思いますが、どのファイルが該当するでしょうか?
なお、文字化けは、文字コードが原因かと思います。CSVファイルを読み込むためのpd.read_csv関数の引数にencodingという引数を付け加えると文字化けを防ぐことができます。詳細はマニュアルを参照してください。
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
P.539のプログラムでエラーがでます。# αを変えて何度もLasso回帰を実行
lasso_alphas, lasso_coefs, _ = linear_model.lasso_path(
X, y, fit_intercept=False) エラーコードは、ValueError: (‘Unexpected parameters in params’, dict_keys([‘fit_intercept’]))
でした。
E.Wさん
管理人の馬場です。
拙著をお読みいただき、ありがとうございます。
sklearnのバージョンの違いが原因で発生するエラーだと思われます。
以下の対応をご検討ください。
1.古いバージョンのAnacondaをインストールする
書籍 p16「古いバージョンのAnacondaのインストール」を参考にして
「Anaconda3 2021.11(Python 3.9.7 64-bit)」をインストールしてください。
ファイルは以下のURLからダウンロードできます。
[URL: https://repo.anaconda.com/archive/%5D
2.引数から「fit_intercept=False」をなくす
以下のようにコードを変更します。
# αを変えて何度もLasso回帰を実行
lasso_alphas, lasso_coefs, _ = linear_model.lasso_path(
X, y)
上記でほぼ同じ結果を再現できるはずです。
参考になれば幸いです。