カオス時系列の基礎とニューラルネットワーク
ランダムなノイズが一切ないのにかかわらず不規則な変動を示すデータのことを「カオス」と呼びます。
ここではカオスの特徴を簡単に説明したうえで、カオスかカオスでないかの判別の方法を記します。
最後に、線形な時系列モデルであるARIMAモデルと機械学習法の一種であるニューラルネットワークをカオス時系列に当てはめてみます。
非線形時系列解析を取り扱うパッケージ「nonlinearTseries」と時系列データへの予測を行うパッケージ「forecast」を使用します。
Rのコードはすべてこちらに載せてあります。
スポンサードリンク
目次
- カオス時系列の基礎
- ロジスティック写像
- ロジスティック写像の特徴
- カオスの判別:リアプノフ指数
- カオスの判別:サロゲートテスト
- ARIMAモデルによるカオス時系列の予測
- ニューラルネットワークによるカオス時系列の予測
1.カオス時系列の基礎
記事の冒頭でも示したように、ランダムなノイズが一切ないのにかかわらず不規則な変動を示すデータのことを「カオス」と呼びます。
例えば、サイコロを投げたとします。どのような目が出るのかは確率的に決まります。このように確率的に変化することを想定したモデルを「確率論的モデル」と呼びます。「サイコロの目が何になるのかわからない」という不確実性を伴います。ランダムに発生するノイズによって、不規則な変動を示します。
一方のカオスは、一切の不確実性を伴わない「決定論的なモデル」です。
例えば、1期前のデータが「0.3」なら、その次は「0.9」になると決まっています。「たまたま0.8になった」ということはあり得ません。偶然の要素が入らないのが決定論的なモデルです。
決定論的なモデルであるのにかかわらず、不規則な変動をするというのはなかなか不思議な話でして、時系列解析をする際にも、普通の「ランダムなノイズ」によって値が変わるということを想定したモデルを使うと、うまく予測ができないこともしばしばです。
次の節からは、決定論的なモデルであるのにかかわらず、不規則な変動をする時系列データを実際に見てみます。
2.ロジスティック写像
カオス時系列データとしてもっとも有名なものが、ロジスティック写像でしょう。
Rを使えば簡単にシミュレートできます。
カオス時系列などの非線形な時系列データを扱うパッケージに「nonlinearTseries」というものがあります。
今回はそれを使ってシミュレートしてみます。
# 必要であればパッケージをインストール
install.packages("nonlinearTseries")
library(nonlinearTseries)
# nonlinearTseriesの関数を使ってロジスティック写像をシミュレーションしてみる
logMap <- logisticMap(
r = 4,
n.sample = 100,
start = 0.4,
n.transient=0,
do.plot=TRUE
)
上記のコードを実行すると、以下のようなグラフが描かれます。
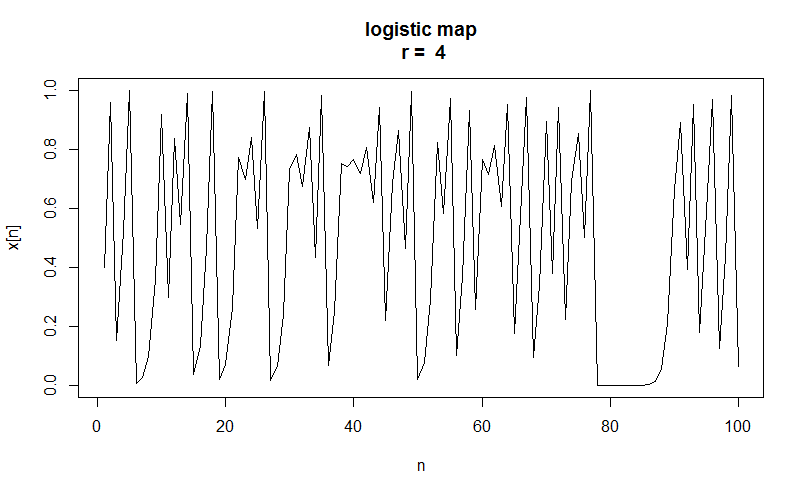
脈絡もなくグネグネとしており、不規則な変動をしているように見えます。
このデータはどのようにして作られたものなのでしょうか。
ロジスティック写像は、名前の通り、有名な「ロジスティック曲線」と密接な関係があります。
ロジスティック曲線は、以下の数式で表されます。
$$ y=\frac{K}{1 + be^{-cx}}$$
Rで実装してみます。
# ロジスティック曲線の例 K <- 1 b <- 3 c <- 1 x <- seq(-5, 10, 0.1) y <- K / (1 + b * exp(-c * x)) plot(y ~ x, type = "l", main="ロジスティック曲線")
こんなグラフになります。

似ても似つかないように見えますが、実はとてもよく似ています。
yの差分をとってみます。
まずはデータを1期ずらします。データをずらすには、embed関数を使います。
embed関数の動きは以下の通りです。
1~5の数値が1つずつずれて2~5と1~4のデータに分かれました。とても便利な関数なので、是非ご銘記ください。
> # embedの使い方
> 1:5
[1] 1 2 3 4 5
> embed(1:5, 2)
[,1] [,2]
[1,] 2 1
[2,] 3 2
[3,] 4 3
[4,] 5 4
これをロジスティック曲線のデータにも適用します。
そのうえで差分をとれば、「1期ずつずらしたときのyの増分」が計算できます。
「yの増分」を縦軸に、「yの値」を横軸に置いたグラフを作ります。
> # データをずらす
> lagData <- embed(y, 2)
> lagData[1:5,]
[,1] [,2]
[1,] 0.002476048 0.002240949
[2,] 0.002735744 0.002476048
[3,] 0.003022595 0.002735744
[4,] 0.003339423 0.003022595
[5,] 0.003689337 0.003339423
>
> # 差分をとる。これが「増加値」になる
> diffData <- lagData[,1] - lagData[,2]
>
> # yの増加値を縦軸に、yの値そのものを横軸に置いたグラフ
> plot(
+ diffData ~ lagData[,1],
+ ylab = "yの増加値",
+ xlab = "yの値",
+ main="yの増加値の変化"
+ )
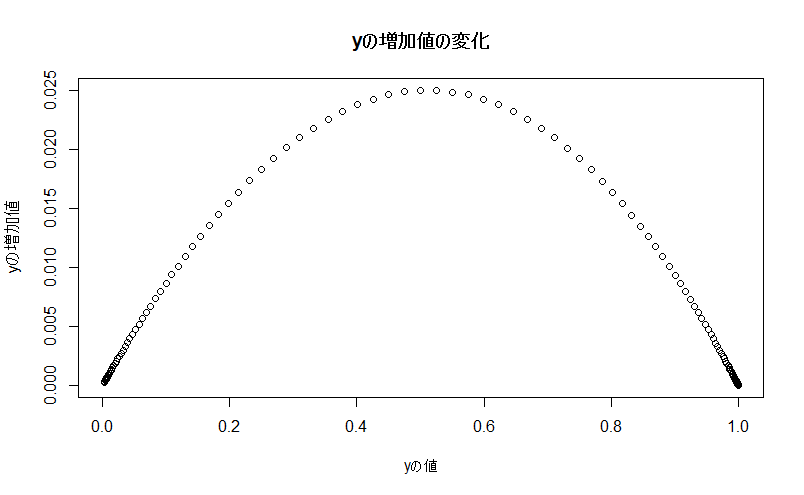
山形のグラフになりました。
これは「yは、yそのものが小さすぎたり大きすぎたりすると、値が増えにくい」逆に「yは中くらいの値(今回の例だと0.5)の時に、最も増えやすい」ことを意味しています。
お次は、ロジスティック写像のデータを、1期ずらしてプロットしてみます。
# ロジスティック写像のデータをずらしてプロットしてみる lagLogMap <- embed(logMap, 2) plot( lagLogMap[,1] ~ lagLogMap[,2], ylab = "今期の値", xlab = "前期の値", main="今期の値と前期の値の比較" )
よく似たグラフになります。

すなわち、ロジスティック写像の時系列データは「前期の値が大きすぎたり小さすぎたりすると、今期は大きな値にならない」逆に「前期の値が中くらいの時に、今期の値は大きくなる」という特徴があるわけです。
ここがロジスティック曲線と対応しています。「写像」という言葉は数学の専門用語なのですが、なんとなく雰囲気をつかんでいただければと思います。
ちなみに、ロジスティック写像は以下の数式であらわされます。
$$ x_t = r \times{x_{t-1}(1-x_{t-1})}$$
ただし、添え字の「t」は時間を表しています。「t」が今期なら「t-1」は前期であることを表しています。
今期の値は、「r × 前期の値 × (1 – 前期の値)」で計算されるわけです。
パラメタrは、ロジスティック写像の動きを変えるパラメタです。
最初にロジスティック写像を計算したときのコードをもう一度見直してみます。
# nonlinearTseriesの関数を使ってシミュレーションしてみる logMap <- logisticMap( r = 4, n.sample = 100, start = 0.4, n.transient=0, do.plot=TRUE )
3行目でパラメタ「r」を4だと定めています。
4行目で取得するサンプルの数を設定し、5行目で初期値を指定しています。
6行目は「データをずらすかどうか」を指定する部分(0なのでずらさないようにしています)で、7行目でグラフを描いてくださいと指定しています。
パラメタ「r」が4で初期値が0.4なので、2期目の値は「4×0.4×(1-0.4) = 0.96」となります。
実際にそうなっていることを確認してください。
> # 2期目の値 > 4 * 0.4 * (1 - 0.4) [1] 0.96 > logMap [1] 9.600000e-01 1.536000e-01 5.200282e-01 9.983955e-01 6.407737e-03 2.546671e-02 9.927264e-02 3.576703e-01 [9] 9.189691e-01 2.978597e-01 8.365572e-01 5.469169e-01 9.911952e-01 3.490899e-02 1.347614e-01 4.664031e-01 [17] 9.954850e-01 1.797850e-02 7.062109e-02 2.625350e-01 7.744415e-01 6.987275e-01 8.420295e-01 5.320632e-01 [25] 9.958878e-01 1.638115e-02 6.445125e-02 2.411891e-01 7.320678e-01 7.845782e-01 6.760610e-01 8.760102e-01 [33] 4.344654e-01 9.828209e-01 6.753596e-02 2.518994e-01 7.537844e-01 7.423739e-01 7.650196e-01 7.190585e-01 [41] 8.080534e-01 6.204124e-01 9.420034e-01 2.185319e-01 6.831028e-01 8.658934e-01 4.644880e-01 9.949556e-01 [49] 2.007584e-02 7.869122e-02 2.899957e-01 8.235927e-01 5.811511e-01 9.736580e-01 1.025923e-01 3.682686e-01 [57] 9.305874e-01 2.583781e-01 7.664754e-01 7.159634e-01 8.134392e-01 6.070235e-01 9.541839e-01 1.748679e-01 [65] 5.771564e-01 9.761875e-01 9.298170e-02 3.373444e-01 8.941727e-01 3.785117e-01 9.409623e-01 2.222088e-01 [73] 6.913283e-01 8.535740e-01 4.999417e-01 1.000000e+00 5.429109e-08 2.171644e-07 8.686572e-07 3.474626e-06 [81] 1.389846e-05 5.559305e-05 2.223598e-04 8.892415e-04 3.553803e-03 1.416469e-02 5.585622e-02 2.109452e-01 [89] 6.657893e-01 8.900556e-01 3.914266e-01 9.528473e-01 1.797174e-01 5.896761e-01 9.678328e-01 1.245300e-01 [97] 4.360891e-01 9.836616e-01 6.428579e-02
この数式を使えば、関数を使わなくても、自分でシミュレーションができます。
# 定義通りに計算してみる
x0 <- 0.4 # 初期値
x <- numeric(100) # カオス時系列を入れる入れ物
x[1] <- x0
r <- 4 # パラメタ
for(i in 2:100){
x[i] <- r * x[i-1] * (1 - x[i-1])
}
結果を比較してみます。
自分で計算したほうは、初期値の0.4が残ったままなので、最初の1つ目のデータを消しておきました。
同じ値になっていることを確認してください。
> # 結果は同じ > x[-1] [1] 9.600000e-01 1.536000e-01 5.200282e-01 9.983955e-01 6.407737e-03 2.546671e-02 9.927264e-02 3.576703e-01 [9] 9.189691e-01 2.978597e-01 8.365572e-01 5.469169e-01 9.911952e-01 3.490899e-02 1.347614e-01 4.664031e-01 [17] 9.954850e-01 1.797850e-02 7.062109e-02 2.625350e-01 7.744415e-01 6.987275e-01 8.420295e-01 5.320632e-01 [25] 9.958878e-01 1.638115e-02 6.445125e-02 2.411891e-01 7.320678e-01 7.845782e-01 6.760610e-01 8.760102e-01 [33] 4.344654e-01 9.828209e-01 6.753596e-02 2.518994e-01 7.537844e-01 7.423739e-01 7.650196e-01 7.190585e-01 [41] 8.080534e-01 6.204124e-01 9.420034e-01 2.185319e-01 6.831028e-01 8.658934e-01 4.644880e-01 9.949556e-01 [49] 2.007584e-02 7.869122e-02 2.899957e-01 8.235927e-01 5.811511e-01 9.736580e-01 1.025923e-01 3.682686e-01 [57] 9.305874e-01 2.583781e-01 7.664754e-01 7.159634e-01 8.134392e-01 6.070235e-01 9.541839e-01 1.748679e-01 [65] 5.771564e-01 9.761875e-01 9.298170e-02 3.373444e-01 8.941727e-01 3.785117e-01 9.409623e-01 2.222088e-01 [73] 6.913283e-01 8.535740e-01 4.999417e-01 1.000000e+00 5.429109e-08 2.171644e-07 8.686572e-07 3.474626e-06 [81] 1.389846e-05 5.559305e-05 2.223598e-04 8.892415e-04 3.553803e-03 1.416469e-02 5.585622e-02 2.109452e-01 [89] 6.657893e-01 8.900556e-01 3.914266e-01 9.528473e-01 1.797174e-01 5.896761e-01 9.678328e-01 1.245300e-01 [97] 4.360891e-01 9.836616e-01 6.428579e-02 > logMap [1] 9.600000e-01 1.536000e-01 5.200282e-01 9.983955e-01 6.407737e-03 2.546671e-02 9.927264e-02 3.576703e-01 [9] 9.189691e-01 2.978597e-01 8.365572e-01 5.469169e-01 9.911952e-01 3.490899e-02 1.347614e-01 4.664031e-01 [17] 9.954850e-01 1.797850e-02 7.062109e-02 2.625350e-01 7.744415e-01 6.987275e-01 8.420295e-01 5.320632e-01 [25] 9.958878e-01 1.638115e-02 6.445125e-02 2.411891e-01 7.320678e-01 7.845782e-01 6.760610e-01 8.760102e-01 [33] 4.344654e-01 9.828209e-01 6.753596e-02 2.518994e-01 7.537844e-01 7.423739e-01 7.650196e-01 7.190585e-01 [41] 8.080534e-01 6.204124e-01 9.420034e-01 2.185319e-01 6.831028e-01 8.658934e-01 4.644880e-01 9.949556e-01 [49] 2.007584e-02 7.869122e-02 2.899957e-01 8.235927e-01 5.811511e-01 9.736580e-01 1.025923e-01 3.682686e-01 [57] 9.305874e-01 2.583781e-01 7.664754e-01 7.159634e-01 8.134392e-01 6.070235e-01 9.541839e-01 1.748679e-01 [65] 5.771564e-01 9.761875e-01 9.298170e-02 3.373444e-01 8.941727e-01 3.785117e-01 9.409623e-01 2.222088e-01 [73] 6.913283e-01 8.535740e-01 4.999417e-01 1.000000e+00 5.429109e-08 2.171644e-07 8.686572e-07 3.474626e-06 [81] 1.389846e-05 5.559305e-05 2.223598e-04 8.892415e-04 3.553803e-03 1.416469e-02 5.585622e-02 2.109452e-01 [89] 6.657893e-01 8.900556e-01 3.914266e-01 9.528473e-01 1.797174e-01 5.896761e-01 9.678328e-01 1.245300e-01 [97] 4.360891e-01 9.836616e-01 6.428579e-02
3.ロジスティック写像の特徴
ロジスティック写像の初期値やパラメタ「r」を変えたときの挙動を見てみます。
まずは、初期値をわずかに変えてみます。
先ほどは0.4スタートだったので、つぎは「0.400000001」を初期値にしてみました。
# 初期値をわずかに変えてみる logMap2 <- logisticMap( n.sample = 100, start = 0.400000001, n.transient = 0, do.plot = F ) # 初期値0.4の時のロジスティック写像と比較 ts.plot( ts(logMap), ts(logMap2), col = c(1,2), lty = c(1,2), lwd = c(2,1), main = "初期値を変えたときの比較" )
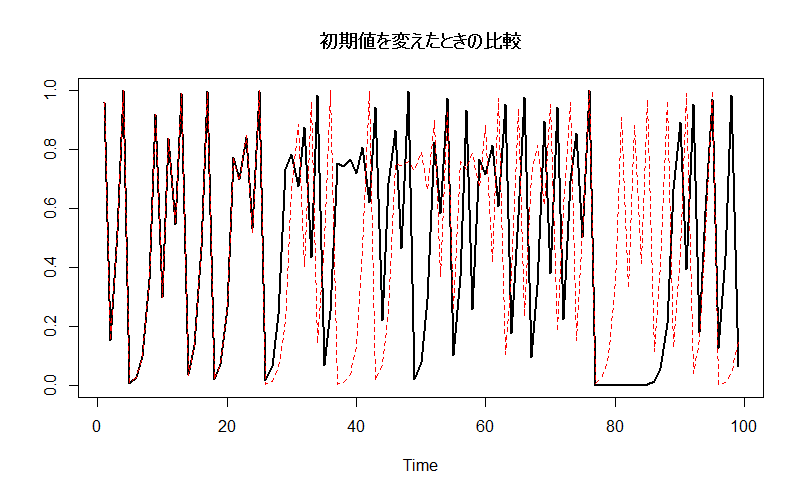
黒い線が、初期値0.4のロジスティック写像を、赤い点線が初期値をわずかに増やしたときの結果を表しています。
最初の20個ほどのデータでは、ほぼ変化がなかったのですが、25期を超えたあたりから大きく値が離れていっているのがわかります。
このように、ほんのわずかな初期値の変化が、最終的には大きな変化をもたらすのがカオス時系列の特徴です。
この現象は「蝶々が羽ばたいた小さな風がいつかは台風になる」というたとえ話から「バタフライ エフェクト」とも呼ばれます。
次は、パラメタ「r」の値を変えてみます。
# パラメタを変えてみる logMap3 <- logisticMap( r = 3.5, n.sample = 100, start = 0.4, n.transient = 0, do.plot = T )
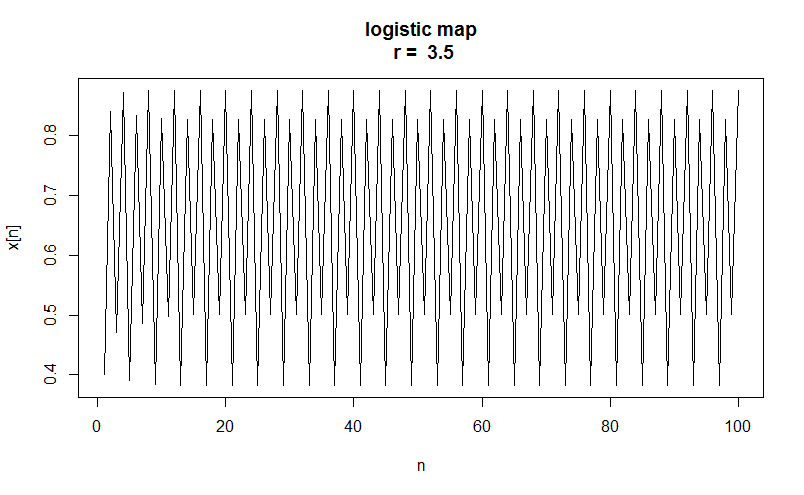
先ほどとは打って変わって、とても規則的な周期変動を示すようになりました。
もちろんこの時系列データはカオスではありません。
パラメタが変わると、ロジスティック写像であっても、カオス的な変動を示さないことがあるということでした。
4.カオスの判別:リアプノフ指数
同じロジスティック写像であっても、パラメタが変わるだけで、カオスかカオスでないかが変わりました。
では、カオスか否かはどのように判別すればよいのでしょうか。
その一つの基準がリアプノフ指数です。
カオスの特徴として「初期値がほんのわずかだけ変化しても、最終的な結果が大きく変わる」というものがありました。
リアプノフ指数は、この特徴を持つか否かを判別する指数です。
リアプノフ指数の計算方法を理解するためには、微分について思い出す必要があります。
ちょっと冗長になりますが、微分の解説もしながら、リアプノフ指数の計算方法を説明します。
まず、グラフにおける「傾き」と呼ばれる値を思い出してください。
横軸がXで、縦軸がYのグラフに線が引っ張ってあって、その傾きが急だと「Xが変化するとYが大きく変化する」ことがわかります。
これと同じ理屈を使います。
横軸が初期値で、縦軸が1期先の値であるグラフに線を引っ張って、その傾きがプラスだと「初期値が変化することによって、将来の値が増える」ことがわかりますね。
傾きの絶対値が大きければ、「初期値が変わると、1期先の値は大きく変わる」と言えます。
で、その傾きを計算する手法が「微分」でした。
微分を使って接線の傾きを計算するというテスト問題を解かれた方は多いかと思います。微分すれば、傾きがすぐに求まります。
次は傾きの組み合わせについて説明します。
例えば、お店に来る人が1人増えると、売り上げが2万円増えるとします。このとき、横軸に「人数」縦軸に「売り上げ」を置いた時の傾きは「2」です。
また、チラシを10枚配るごとに、1人のお客さんを店に呼ぶことができるとします。このとき、横軸に「チラシの枚数」縦軸に「人数」を置いた時のグラフの傾きは「0.1」です。
では、チラシを1枚多く配ると、売り上げはどれだけ増えるでしょうか。
0.1 × 2 = 0.2万円
となり、チラシ1枚につき0.2万円儲けが増えることになります。
原因が連鎖していくと、傾きが掛け合わされていくことに注目してください。
カオス時系列の初期値が変わると、1期先の値が変わります。
1期先の値が変わると、2期先の値も変わります。
その変化の度合いは、微分により求まった係数をかけ合わせていけば、ずっと将来の値に対しても、初期値の変化がもたらす影響を調べることができます。
というわけで、以下の値が重要な意味を持ちます。
$$ \vert \displaystyle \prod_{ t = 0 }^{n-1} f'(x_t) \vert$$
ただし、f’は関数の微分を表す記号で、Πは「掛け合わせる」という記号です。xtは「t 期の時系列の値」です。nはサンプルサイズです。100期あればnは100です。
要するに、微分された値を、過去から順番に掛け合わせていっているんですね。
掛け算は計算が難しいので、対数をとって足し算に直します。
さらに、足された値の平均値をとるため、サンプルサイズで割ります。
$$ \hat{\lambda}_{max} = \frac{ 1 }{ n } \displaystyle \sum_{ t = 0 }^{n-1} \log( \vert f'(x_t) \vert )$$
こうして求まった$$ \hat{\lambda}_{max} $$ を、最大リアプノフ指数(の近似値)と呼びます。
本来は無限大のサンプルサイズが必要なのですが、そんなデータは得られないので、近似値となっています。実データではこの値を使うことになります。
このリアプノフ指数が正の値になれば、初期値が変わることによって、将来の値が変わっていくことがわかります。
逆に、周期的な変動を示すデータなど、初期値の影響が少ない場合は、リアプノフ指数が負になります。
計算してみましょう。
まずはロジスティック写像を微分します。
ロジスティック写像の定義は以下の通りでした。
$$ x_{t+1} = f(x_{t}) = r \times{x_{t}(1-x_{t})}$$
微分します。
$$ f'(x_{t}) = -2rx_{t} + r$$
あとは、この値を計算して、絶対値をとって、対数をとって、足し合わせていけばOKです。
Rでやってみます。
まずは微分係数を求める関数を作ります。
# ロジスティック写像の微分
logMapDifferential <- function(r, x){
return(-2 * r * x + r)
}
これで、パラメタrとデータxを突っ込めば、すぐに微分係数が求まります。
カオス時系列に対するリアプノフ指数を計算します。
パラメタrは4を指定します。
> # リアプノフ指数が正なので、カオス > sum(log(abs(logMapDifferential(4, logMap))))/ 99 [1] 0.7010254
ちゃんとプラスの値になりました。
なお、absが絶対値を、logが対数を、sumが合計を計算する関数です。
次は、同じロジスティック写像でも、周期的な変動を示す「パラメタrが3.5」のデータでリアプノフ指数を計算してみます。
> # これはカオスではない(周期的変動)なので、リアプノフ指数も負になる > sum(log(abs(logMapDifferential(3.5, logMap3))))/ 99 [1] -0.8075111
負の値になりました。初期値依存性が低く、やはりカオスではなかったということです。
リアプノフ指数さえ計算できれば、カオスかどうかがある程度判別できます。
大変便利な指標なのですが、一つ大きな問題があります。
それは、微分しなければいけないところです。
今回は時系列データがロジスティック写像だとわかっている状態で計算しました。なので、ロジスティック写像の方程式はわかっており、微分することも簡単です。
しかし、実データだと微分係数を求めるのはなかなか難しいです。
実データに対してリアプノフ指数を計算する方法も提案されていますが、ノイズが加わるとすぐに値が大きく変わってしまうという欠点があります。
リアプノフ指数は、カオスの判別をするのにとても重要な指標ですが、これだけでは実データへ適用することが少々困難です。
そこで登場するのが、サロゲートテストです。
5.サロゲートテスト
サロゲートテストはサロゲート法とも呼ばれます。
これはリアプノフ指数の計算時の問題を逆に応用して、カオスかどうかの判別をする方法です。
カオス時系列などの非線形なデータに対してリアプノフ指数を計算するとき、データにノイズが含まれていると、リアプノフ指数が大きくなってしまうという問題があります。
しかし、実は、カオスではない線形のデータに対してならば、ノイズが含まれていても、リアプノフ指数の値はそれほど変わりません。
データが線形か非線形かで、「ノイズが加わることによるリアプノフ指数の変化の大きさ」が変わるわけです。
この特徴を利用します。
データに対して無理やりノイズをくわえてやり、リアプノフ指数が有意に大きくなれば、そのデータは、少なくとも線形のデータではないことがわかります。
サロゲートテストは、nonlinearTseriesパッケージのsurrogateTestという関数を使えば実施することができます。
カオス時系列データに対してやってみます。
> # リアプノフ指数が正だったカオス時系列は有意 > surrogateTest( + time.series = logMap, + significance = 0.05, + K = 1, + one.sided = FALSE, + FUN = timeAsymmetry + ) Computing statistics Null Hypothesis: Data comes from a linear stochastic process Reject Null hypothesis: Original data's stat is significant larger than surrogates' stats $surrogates.statistics [1] 0.0042659240 -0.0109473303 -0.0067968422 0.0036488529 -0.0136728821 -0.0045238834 0.0172539099 0.0024994185 [9] -0.0031088030 0.0079766897 0.0058793624 -0.0105897368 0.0033514877 0.0099003654 0.0017537882 -0.0008365056 [17] 0.0129718729 0.0065479001 -0.0033437734 -0.0134248665 0.0062768042 0.0163935058 0.0007909881 0.0107432495 [25] 0.0007322799 0.0048542059 0.0106389710 -0.0075901774 -0.0015996523 -0.0049119257 -0.0095919269 -0.0081788208 [33] 0.0008401459 0.0083525043 -0.0024713423 0.0004137995 0.0054532041 0.0018706020 0.0107815256 $data.statistic [1] 0.02682431 attr(,"class") [1] "surrogateTest"
11行目と12行目に注目してください。
Null Hypothesis: Data comes from a linear stochastic process
Reject Null hypothesis
帰無仮説に「データは線形の確率的プロセスから発生した」とあり、その帰無仮説が棄却「Reject」されたと書いてあります。
4行目のsignificance = 0.05で、危険率を設定しているので、危険率0.05で、「データは線形の確率的プロセスから発生した」という帰無仮説を棄却できたことになります。
やはり、こいつは線形のデータではなかったということです。
次は、ただの正規分布に従う乱数に対して、サロゲートテストを行ってみます。
> # 正規乱数を入れてみても、棄却されない > set.seed(1) > surrogateTest( + time.series = rnorm(100), + significance = 0.05, + K = 1, + one.sided = FALSE, + FUN = timeAsymmetry + ) Computing statistics Null Hypothesis: Data comes from a linear stochastic process Accept Null hypothesis $surrogates.statistics [1] -0.121725969 0.191122267 0.001487573 0.027470936 0.064432098 0.137131993 -0.149096062 0.030608521 [9] 0.220701275 -0.498798624 -0.231652771 -0.034873177 -0.033777567 0.064964664 -0.226848624 -0.144154920 [17] 0.090597889 0.016906168 0.035641608 0.085692971 -0.129107242 -0.319682829 0.114451414 0.029034354 [25] -0.025254347 -0.188000184 -0.085623117 0.144043274 0.193473326 0.023565973 0.068236046 -0.005789114 [33] -0.058857671 -0.010824415 -0.157127104 -0.066048004 0.037907767 0.170882806 0.028963089 $data.statistic [1] -0.2576197 attr(,"class") [1] "surrogateTest"
今度は棄却されませんでした。
サロゲートテストにより、データが非線形なのか、線形でノイズが加わっているだけなのかをある程度判別ができます。
カオスかどうかをはっきり見分ける手法ではないことに注意が必要ですが、データを表す方程式などがわかっていなくてもすぐ適用できる便利な手法です。
6.ARIMAモデルによるカオス時系列の予測
標準的な時系列解析手法であるARIMAモデルを使って、カオス時系列の予測を試みます。
ただ、結論から言うと、線形なモデルであるARIMAモデルは、非線形なカオス時系列に対しては無力です。
ARIMAモデルの推定にはforecastパッケージの「auto.arima」関数を使います。
こちらの使い方は、時系列解析理論編と実践編に詳しく書いてあるのでそちらをご参照ください。
ARIMAモデルを推定する場合は「何期前までのデータを使うか」など様々なパラメタを指定しなければならないのですが、「auto.arima」関数は、その名の通り、自動で最適なモデルを選んでくれます。
# 必要であればパッケージをインストール
# install.packages("forecast")
library(forecast)
logMapArima <- auto.arima(
logMap,
ic = "aic",
trace = T,
stepwise = F,
approximation = F
)
stepwise=Fにするところと、approximation=Fにするところに注意してください。
ここをT(TRUE)にしてしまうと、計算を端折ってしまい、正確な結果が出なくなってしまいます。
選ばれた最適なモデルはこちらです。
>
> # arima(0,0,0)すなわち、ただのホワイトノイズだとみなされてしまった。
> logMapArima
Series: logMap
ARIMA(0,0,0) with non-zero mean
Coefficients:
intercept
0.4919
s.e. 0.0361
sigma^2 estimated as 0.1301: log likelihood=-39.02
AIC=82.03 AICc=82.16 BIC=87.22
切片(intercept)以外何もありません。
これは「この時系列データは、過去の値を使って予測することができない、ただのホワイトノイズだ」とみなされてしまったということです。
もちろん、予測などまったくできません。
確認のため、カオス時系列データを20期先まで追加でシミュレーションにより作成し、それを予測させてみます。
# 101期目以降を予測しても、もちろん当たらない logMapNext <- logisticMap( r = 4, n.sample = 120, start = 0.4, n.transient = 0, do.plot = FALSE ) plot(forecast(logMapArima, h=20)) lines(logMapNext)
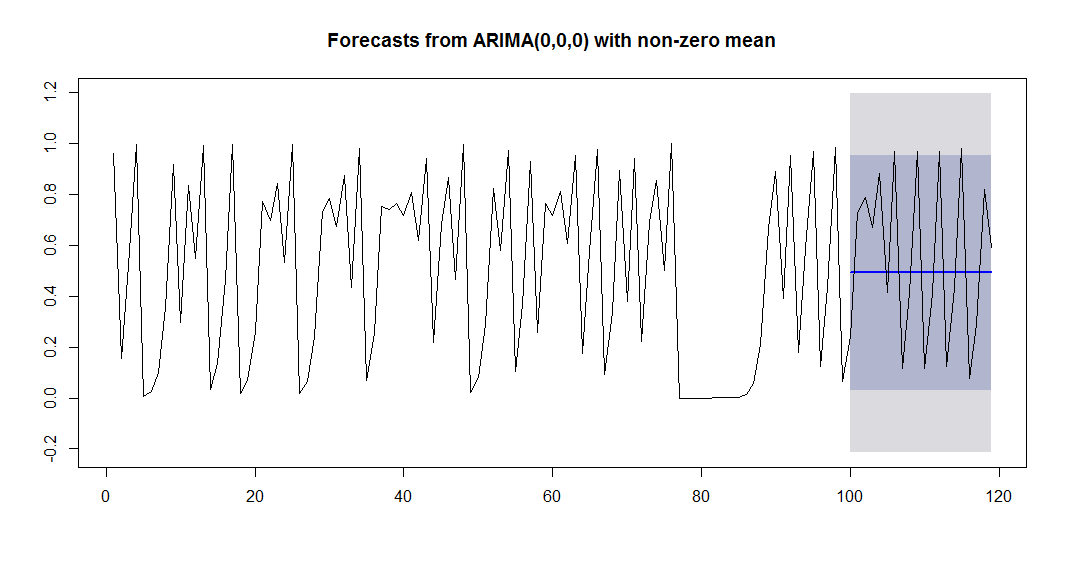
10行目で予測を出してその結果を図示しています。
11行目で120期までを含む将来のシミュレーションデータを追加で描画しています。
上の図の濃い青の線が予測値なのですが、将来の変動をまるで予測できていないことがわかります。
予測誤差などを計算してみます。
RMSEはRoot Mean Squared Errorの略で、予測誤差を2乗したものの平均値の平方根をとったものです。
ほかにもMAE(Mean Absolute Error)のように、予測誤差の絶対値の平均をとった指標などもあります。
これらはまとめてaccuracy関数で計算ができます。
定義通りに計算した後、accuracy関数を使って、同じ値を計算してみました。
> # 予測精度の計算
> f <- forecast(logMapArima, h=20)$mean
> sqrt(sum((f - logMapNext[100:119])^2)/20) # RMSE
[1] 0.322963
> sum(abs(f - logMapNext[100:119]))/20 # MAE
[1] 0.2871588
> accuracy(forecast(logMapArima, h=20),logMapNext[100:119])
ME RMSE MAE MPE MAPE MASE ACF1
Training set -2.882143e-16 0.3588533 0.3256399 -1.220284e+07 1.220288e+07 0.8533711 0.09952549
Test set 5.813548e-02 0.3229630 0.2871588 -6.643936e+01 1.060108e+02 0.7525275 NA
accuracy関数はなかなか便利でして、予測モデルを作るのにつかわれたトレーニングデータに対する予測精度と、テストデータへの予測精度を一覧にして確認できます。
定義通りに計算した結果とTest setの行の値が一致していることを確認してください。
RMSEやMAE以外の値の意味はこちらの本家のサイトなどを確認してください(英語です)。
7.ニューラルネットワークによるカオス時系列の予測
残念ながらARIMAモデルではカオス時系列の予測ができませんでした。
次は、機械学習法の一種である、ニューラルネットワークを使った予測を試みます。
ニューラルネットワークに関する詳細はここでは説明しませんが、forecastパッケージの「nnetar」関数を使えば、簡単にモデル化と予測をすることができます。
やってみます。
set.seed(1) logMapNnet <- nnetar( y = logMap, p = 1, size = 4 ) plot(forecast(logMapNnet, h=20)) lines(logMapNext)
この関数は、乱数が使われており、計算するたびに値が変わるので、set.seed(1)と固定してあります。
3行目のyでデータを指定し、4行目のpで「予測のために、何期前までのデータを使うか」を指定します。ロジスティック写像は1期前の値を使うだけで記述できるはずなので、p=1としてあります。
5行目のsize=4は、ニューラルネットワークの「中間層」あるいは「隠れ層」と呼ばれる層のニューロンの個数を表しています。
4を指定していますが、これは予測精度が高くなるように、私が勝手に調整した結果です。
予測は「auto.arima」関数と同じく「forecast」関数を使えば計算できます。
その結果をplotで図示しました。
9行目は、予測の答え合わせのために、120期までの将来の値を追加で描画したものです。
青い線が予測値、黒い線が実測値です。
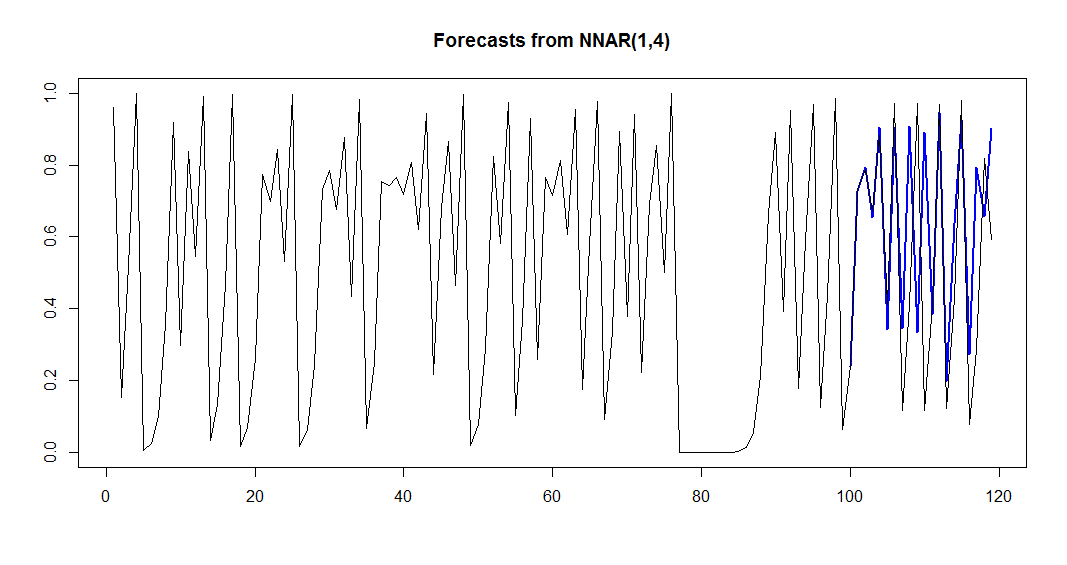
グラフを見ると、ある程度は予測ができていそうに見えます。
> # ニューラルネットワークの予測精度
> accuracy(forecast(logMapNnet, h=20),logMapNext[100:119])
ME RMSE MAE MPE MAPE MASE ACF1
Training set -4.670865e-05 0.001403801 0.001243891 -67427.67570 67428.2049 0.003259737 -0.1005602
Test set -8.816197e-02 0.298327364 0.193823237 -72.34627 85.0214 0.507932678 NA
RMSEやMAEはARIMAモデルを使った時よりも減少しました。
ただし、トレーニングデータを使った時の予測誤差と比べて、テストデータでの予測誤差が相当に増えています。将来を予測することはなかなか難しいようです。
また、グラフをよく見てもらえるとわかりますが(グラフをクリックすると拡大します)、最初の数期の間はほぼ完全に予測ができています。予測期間が長期になると当たりにくくなるようです。
これは当然の話で、カオス時系列は、初期値がほんの少しでも変わると、長期間先のデータでは値が大きく変わるのでした。初期値がほんの少し変わっただけでも値がぶれるのに、長期の予測ができると思うほうがおかしいですね。
予測を5期先までにすると、とてもよくあたっていることがわかります。
(2018年4月25日:コードが動かなかったので修正しました)
> # 5期先までのみを予測する
> accuracy(forecast(logMapNnet, h=5),logMapNext[100:104])
ME RMSE MAE MPE MAPE MASE ACF1
Training set -4.670865e-05 0.001403801 0.001243891 -6.742768e+04 67428.204880 0.003259737 -0.1005602
Test set -1.577557e-03 0.012511571 0.009942588 3.533122e-02 1.380945 0.026055519 NA
カオス時系列に対しては、機械学習法を用い、さらに短い期間だけを予測するという工夫が必要です。
なんでもARIMAモデルではなかなか難しいようですね。
逆に言えば、機械学習法の有効性がわかる例でもあります。
なお、ニューラルネットワークではなく、ARモデルの拡張版であるTARモデルなどを適用することも考えられます。
線形時系列モデルの拡張版を使うことも検討してみてください。
参考文献
|
非線形時系列解析 カオス時系列を含む、非線形な時系列データへの解析方法が書かれた本です。 カオス時系列以外にも長期記憶過程の解説などもあり、なかなか充実した本でした。 私がこの記事を書こうと思ったきっかけとなった本でもあります。 ただし、機械学習法の記述は一切ありません。 |
 |
|
ソフトコンピューティングと時系列解析―ファジイ・ニューロによる予測入門 名前の通り、ニューラルネットワークなどを用いた時系列解析の方法が書かれた本です。このようなテーマの本はとても少ないため貴重です。 ファジィ理論についても記載があり、こちらも参考になりました。 |
 |
|
カオスとフラクタル 文庫で読めるカオスの入門書です。カオスって何だろうと思ったら、まずはこの本から入るのがおすすめです。 |
 |
|
ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装 RではなくPythonという言語を使っているうえに、Deep Learningというニューラルネットワークの発展形を扱った本です。 それにもかかわらず、ニューラルネットワークの解説としては、この本が抜群にわかりよいです。「驚異的」といってもよいほど質の良い本だと思います。 ニューラルネットワークの関連書籍をたくさん挙げようかなとも思ったのですが、これほど素晴らしい本が出てしまった以上、この一冊だけ挙げておくにとどめておきます。 |
 |
書籍以外の参考文献
・nonlinearTseriesパッケージのPDF資料。
・forecastパッケージのPDF資料
スポンサードリンク
更新履歴
2016年10月23日:新規作成
2018年4月25日:ニューラルネットワークによる予測が動かなかったのでコードなどを一部修正しました。
